


The best big data file format
January 25, 2023


I’m honored to be able to share the stage with such incredible leaders of the data science world on March 1st where I’ll cover practical LLM tips over the full NLP lifecycle. I’ll be joined by…
Jon Krohn: Co-founder and Chief Data Scientist at Nebula, author, and host of the SuperDataScience podcast will be hosting the event and guiding conversations.
Sinan Ozdemir: The A.I. entrepreneur and author will introduce the theory behind Transformer Architectures and LLMs like BERT, GPT, and T5.
Melanie Subbiah: A first author on the original GPT-3 paper, she'll lead interactive demos of the broad range of LLM capabilities.
If you don't have access to the O'Reilly online platform through your employer or school, you can use the SuperDataScience special code "SDSPOD23" to get a 30-day trial and enjoy the conference for free!
Now on to our regularly schedule ML content.
Column-oriented storage
If you’ve spent hours trying to debug text stored in CSVs, then you’re not alone. When I worked at old-fashioned companies that weren’t very technologically advanced, I would often be emailed a CSV and be expected to train a model using some columns. I hate using CSVs. They’re extremely slow and bloated and I’ll spend the next 3 minutes of your time convincing you to never use them again.
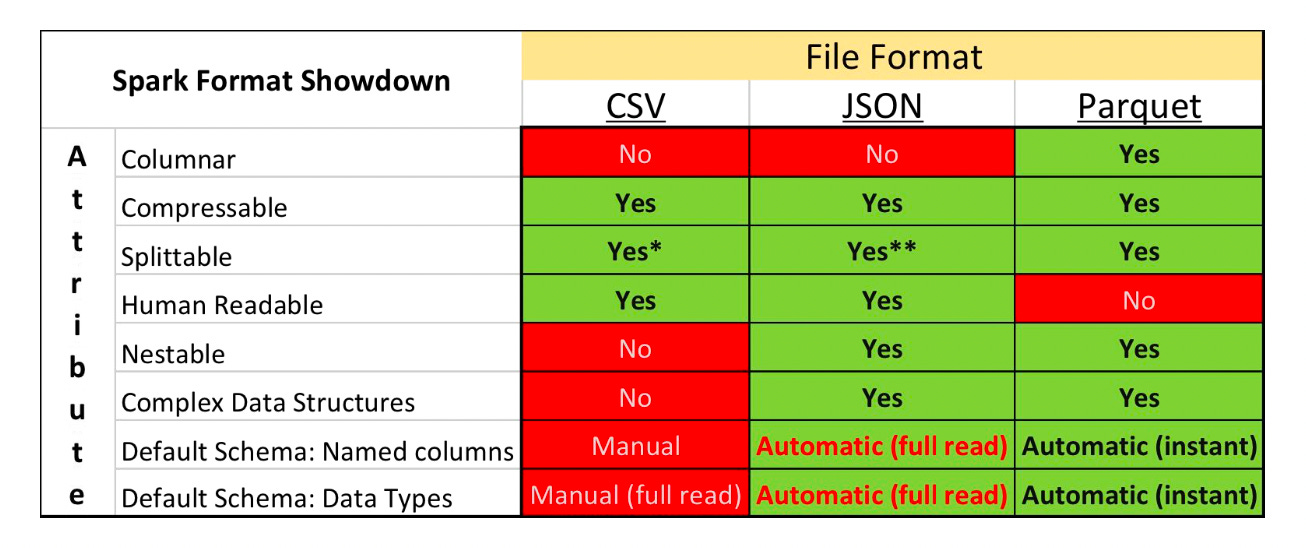
CSVs use row-oriented storage which is great for being able to visualize data and adding rows, but kinda suck for everything else. They require loading in data row by row which in many cases isn’t optimal. For example, if you’re finding the average of a column, using a CSV you’d be required to load each row into memory. A better choice in cases such as this would be to use Parquet:
The parquet file format was developed at Twitter and Clouder in 2013. It’s now an Apache project, the world’s largest open source project, and it’s the recommended storage for Spark. As a highlight:

Parquet takes 87% less space and queries 34x faster (src).
It accomplishes this by storing data in a column-oriented storage. Now if we want to find the average of all the values in a column, we can independently load that column and run our computation. Since the values are stored on a per-column basis, this means you can apply compression independently on each column. You can’t do this with a row-oriented file since each row would contain multiple data types. Column-oriented storage allows for partial decoding, so if you’re querying a specific value only the necessary columns will be decoding.

One of the advantages CSV or JSON has is how ubiquitous they are. JSONs are the standard format for transfering data between applications, in cloud computing, or in databases. But Parquet is cross-platform so it can be ingested in Java, C++, Python, or Scala.
Instead of using this
df = pd.read_csv('data/prices.csv')
df.to_csv('data/prices.csv')this simple change can run up to ~50x faster (src)!
df_parquet = pd.read_parquet('data/prices.parquet')
df.to_parquet('data/prices.parquet')