


FlashAttention: the secret behind longer context
May 17, 2023

If you’ve been using Transformers for the past few years, like me, you would have been shocked by the increase in context length that models such as GPT-4 can accomplish. Memory used by Transformers scales quadratically to the sequence length. This is a result of the self-attention module at the heart of Transformers which has time and memory complexity quadratic to sequence length. That means that having a larger context window was thought to be impossible with the current GPU hardware constraints.
FlashAttention, a technique developed by Stanford researchers, is the reason for the increased context window for current state-of-the-art LLMs. Although GPT-4’s technical paper was never released, practitioners are almost certain that FlashAttention is the reason for the increased context window of 32k. Open-source models, such as Vicuña, a recent LLM we covered here on Let’s Talk Text, use FlashAttention to increase Llama’s context window from 512 tokens to 2048 tokens. Here are some of the main advancements that FlashAttention enables:
3x speedup on GPT-2 training
15% speedup on BERT-large training
7.6x faster attention computation on GPT-2
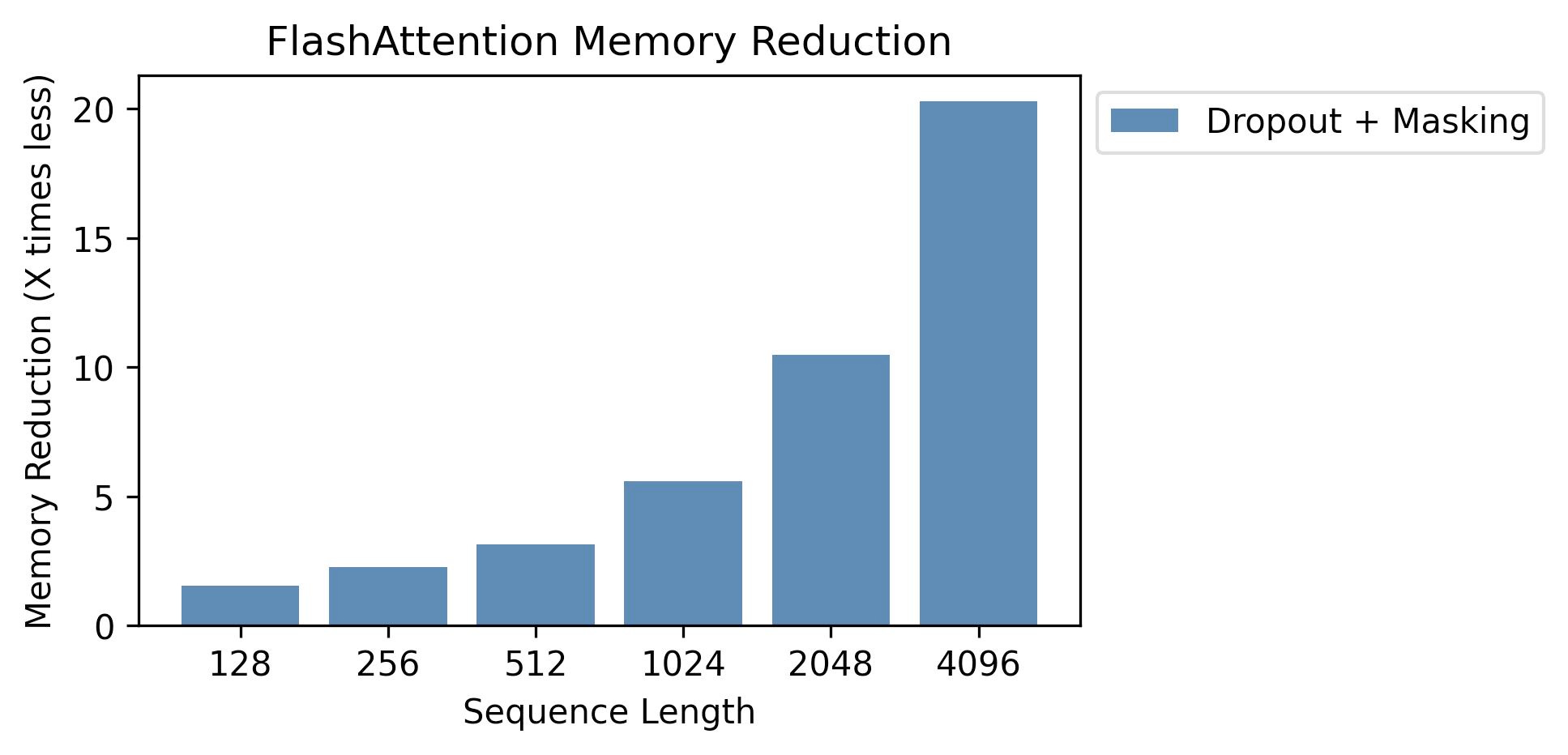
10x memory savings at a sequence length of 2k tokens, 20x at 4k
Enables Transformers to have much longer sequences, up to 64k tokens using block-sparse FlashAttention (a mechanism that reduces computation time and the memory requirements of the attention mechanism by computing a limited selection of similarity scores from a sequence rather than all possible pairs)
As mentioned, FlashAttention improves the time and memory complexity of the self-attention module. Currently, in the self-attention module, the attention matrix that is computed is read and written to the GPU’s high bandwidth memory (HBM). This component of the GPU’s memory is relatively slow, compared to the SRAM which is on-chip and much faster. FlashAttention improves on this by computing this attention with fewer HBM accesses and replacing them with computation on SRAM.
This is the current attention implemented by packages such as PyTorch and TensorFlow:

FlashAttention changes this standard attention implementation in two main ways:
The attention computation gets restructured so instead of the softmax being applied on the entire attention matrix, it is incrementally performed on blocks. This technique is known as tiling.
The softmax normalization factor is stored on-chip in the forward pass to quickly recompute attention on-chip in the backward pass. Before, the attention matrix was read from HBM which was the bottleneck.
The combination of these techniques results in 9x fewer HBM accesses compared to the standard attention and allows the memory to scale linearly to the sequence length. Here’s how this new algorithm would look with those two improvements:

If you’re interested in using FlashAttention, you can check out the GitHub repository here. FlashAttention has already been integrated into PyTorch, HuggingFace, and DeepSpeed. The full list of integrations can be found here.