


Microsoft's new document AI model
October 12, 2022

Matrix multiplication is all you need.
—Bojan Tunguz, Machine Learning at Nvidia
It turns out there are five different ways to multiply matrices together. In the future, we’ll do a deep dive to learn why matrix math is so important in ML and why it’s critical to do it as efficiently as possible.
Model review
DiT
Ever wanted a model that can parse hundreds of pages of legal documents for you?
Document Image Transformer (DiT) is a vision-only transformer-based document AI model made by Microsoft that just came out a few months ago. It achieves state-of-the-art results on various tasks including document classification, document layout analysis, and table detection. Thanks to HuggingFace, you can test out DiT’s capabilities yourself too, just upload a JPG and click submit. Here’s an example of what layout analysis looks like from DiT.

How does DiT outperform previous models? It uses a self-supervised approach to train on large-scale unlabeled text images. No supervised counterparts exist due to the lack of human-labeled document images.
Masked image modeling (MIM)
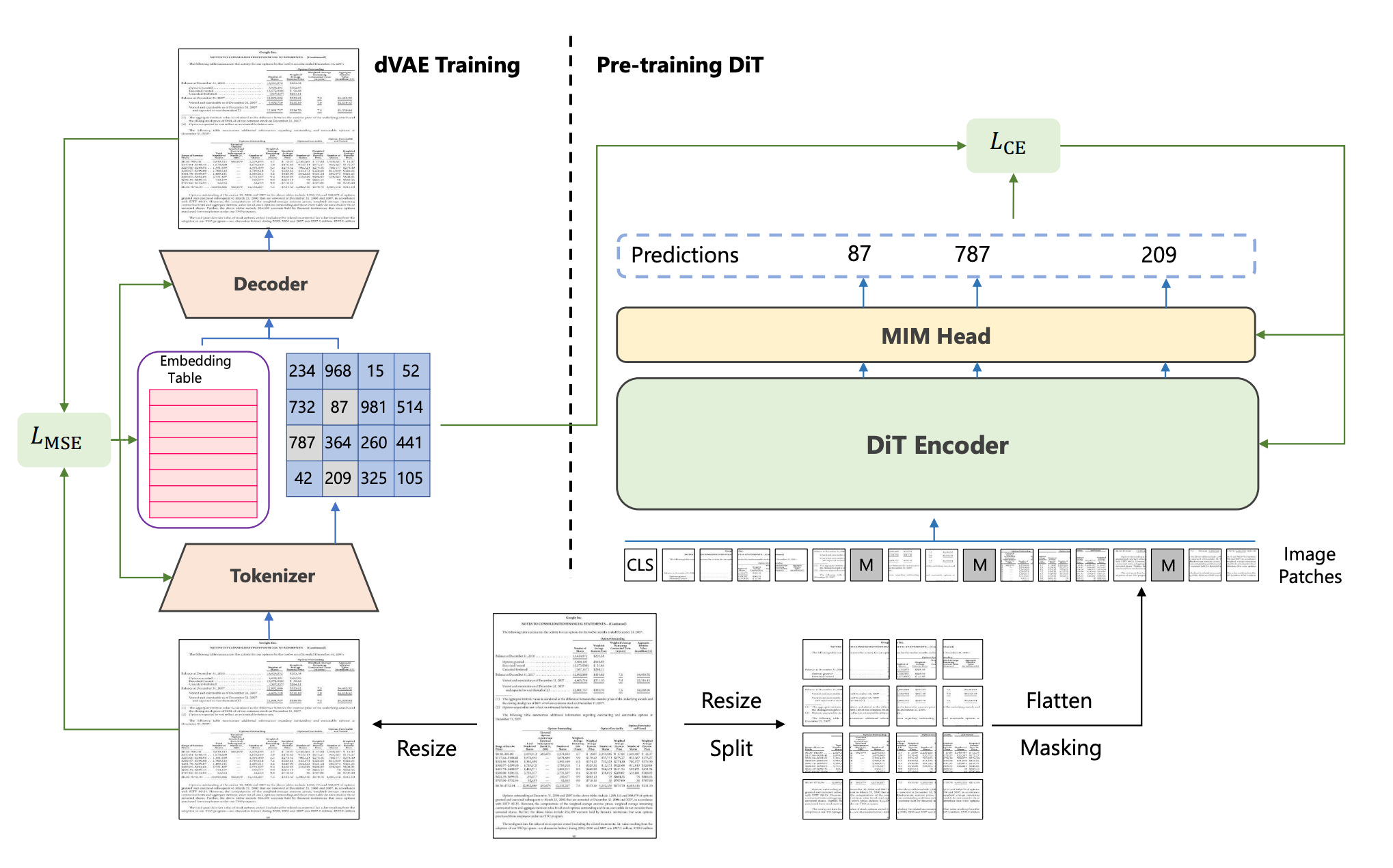
A common way to perform self-supervised learning with images is to use a technique called masked image modeling (MIM). This approach helps train the encoder portion of a transformer model by randomly masking parts of the image and attempting to predict the missing pieces. Each image gets split up into 196 non-overlapping 16x16 patches. These patches get a 1d position embedding which denotes the order of their patch in the image. From here, two different things happen:
An image tokenizer uses this information to create an abstract, high-dimensional, numeric representation of the image patches.
Some portion of the image patches are masked and fed into the transformer, which attempts to recover the abstract, high-dimensional, numeric representation that was created by the tokenizer.
Guessing these missing pieces trains the transformer model to build some sort of understanding about images and in our case, document images.
Auto-encoder
So how does this tokenizer create this abstract, high-dimensional, numeric representation of the image patches? The specific image tokenizer used by DiT is called a discrete variational auto-encoder (dVAE). In short, it is an unsupervised neural network that learns how to efficiently compress and encode data and then learns how to reconstruct the data back from the reduced encoded representation to a representation that is as close to the original input as possible. In our case, the auto-encoder takes in an image, creates an embedding of the representation, then tries to recreate the image using only the information from the embedding. The model here gets penalized based on the differences in the reconstructed image. In the beginning stages, the reconstructed image may not look remotely like the original. But by doing this many times, the encoder part of this learns to filter out unnecessary data from the image and produces high-quality embedding representations. Eventually, we’ll be able to get a very similar-looking reconstructed image. Think of it as a way to ultimately just compress the large amounts of image data (each pixel in the image X the color of each pixel) into a small vector of numbers that captures all the relevant data and filters out the noise.
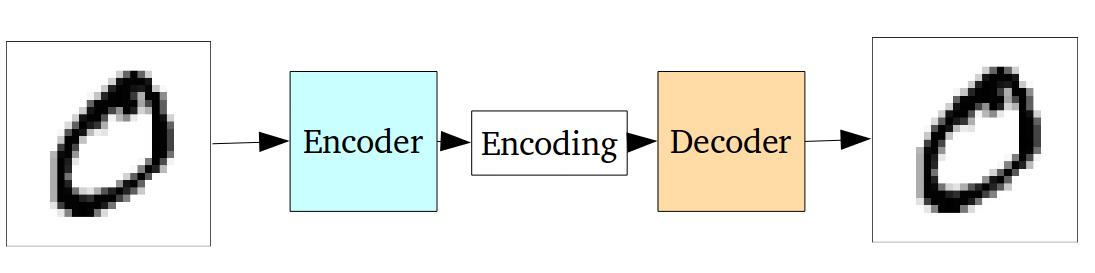
After the training procedure is finished, we’ll use the encoder portion of this model as our image tokenizer.
A brief history of the models that have influenced DiT
October 2020: ViT, a transformer-based model trained with supervised learning classifies images. This was the first time transformers were used in vision, and ViT attained excellent results.
February 2021: DALL-E, the famous model from OpenAI, uses transformers to generate digital images from natural language descriptions.
June 2021: BEiT builds on ViT by using DALL-E’s dVAE and creating a masked image modeling task to use self-supervised pre-training.
July 2022: DiT applies the principles from all of the above models to document AI and achieves state-of-the-art results.
Bringing it all together
Because of masked image modeling, DiT could be trained on a huge amount of data, about 42 million document images. Additionally, instead of just using DALL-E’s dVAE as the BeIT model did, the dVAE in this DiT was trained from scratch on those same 42 million document images. DALL-E’s dVAE was trained on a ton more data (400 million images), but these were all types of images, whereas DiT’s dVAE used only document images resulting in much stronger image representations.
Downstream Tasks
Document image classification: predicting 1 of 16 classes relating to the type of document e.g. letter, form, email, advertisement, science report, etc.
Document layout analysis: detect regions of elements of the document such as title, list, figure and tables
Table detection: predict the bounding boxes of tables in the document
Practical applications
Universal approximation theorem
Shoutout to Pranab for suggesting this week’s practical application. If you’d like to choose a topic to be covered, feel free to reply directly to this email and let me know.
The fundamental goal of machine learning is to model some function that takes as input x and outputs a y. The challenge is that we will never know what that function is, but we can see the x’s that enter the function and the y’s that come out of it. Here’s an example of what one of those functions could look like:
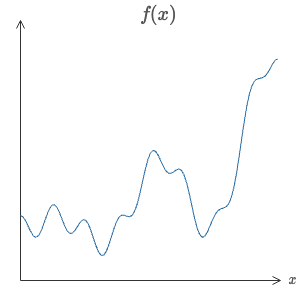
The universal approximation theorem states that regardless of how complex a continuous function is, there is guaranteed to be a neural network that can model it.
A feedforward network with a single layer is sufficient to represent any function, but the layer may be infeasibly large and may fail to learn and generalize correctly.
This is true for any number of inputs and outputs. That’s really quite crazy to think about! The key to a neural net’s ability to approximate any function is that they incorporate non-linearity into its architecture—each layer has an activation function that applies a non-linear transformation to the output of that layer.
